
Creating a Spicetify Extension for Song Ratings and Recommendations with React and Random Forest ML


 brimell
brimellThis post is about how I made the Spicetify extension that allows users to rate songs and leverages a random forest machine learning (ML) model to recommend new tracks based on those ratings. This project was a fun blend of frontend development using React and the power of machine learning.
What is Spicetify?
Spicetify is a powerful tool that allows users to customize their Spotify desktop app experience. It enables theme modifications, CSS injection, and the addition of custom extensions. I chose Spicetify for this project because it offers a flexible platform to enhance the Spotify interface with personalized features.
Building the Extension with React
To create the song rating extension, I used React, a popular JavaScript library for building user interfaces. React’s component-based architecture and state management capabilities made it an ideal choice for developing a dynamic and responsive extension.
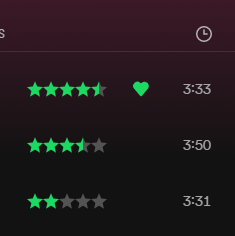
How to install it
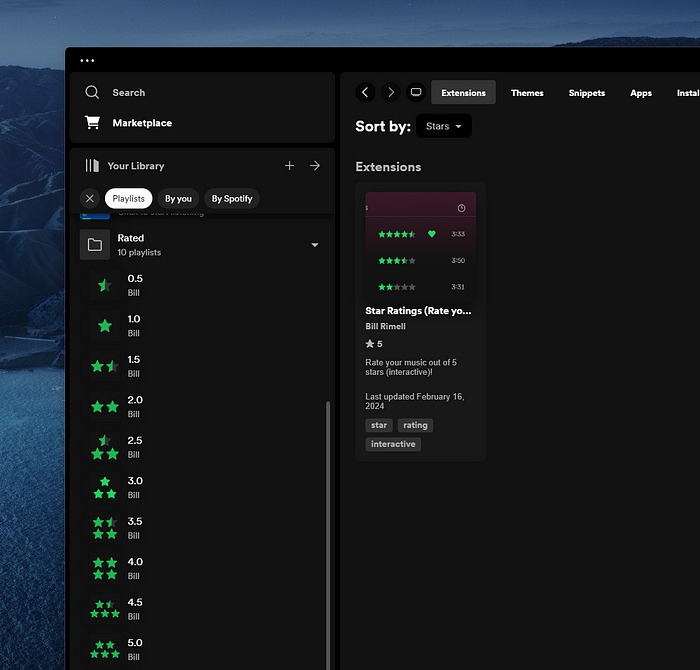
Go to the Spicetify marketplace and search for Star Ratings and it should come up. After clicking on it you can then click install. Or you can install it manually by placing the star-ratings.js file from the GitHub page into your Spicetify extensions folder.
Implementing the Recommendation Model
Gathering Data for the Machine Learning Model
Fetching User Playlists and Tracks
To gather data, I fetched all the user’s playlists and extracted the tracks from playlists named after ratings (e.g., “1.0”, “2.0”, etc.). Here is how I did it:
from auth import sp
def get_all_user_playlists():
playlists = []
results = sp.current_user_playlists(limit=50)
playlists.extend(results['items'])
while results['next']:
results = sp.next(results)
playlists.extend(results['items'])
return playlists
Then, I fetched the audio analysis and features for each track and stored them in a CSV file for further use:
import pandas as pd
from utils import fetch_all_playlist_tracks
playlists = get_all_user_playlists()
tracks = []
for playlist in playlists:
if playlist['name'] in ["1.0", "2.0", "3.0", "4.0", "5.0"]:
playlist_tracks = fetch_all_playlist_tracks(playlist['id'])
for track in playlist_tracks:
audio_features = sp.audio_features(track['track']['id'])[0]
audio_analysis = sp.audio_analysis(track['track']['id'])
track_data = {**track['track'], **audio_features, **audio_analysis}
track_data['rating'] = float(playlist['name'])
tracks.append(track_data)
df = pd.DataFrame(tracks)
df.to_csv('rated.csv', index=False)
Implementing the Random Forest Model
A random forest is a versatile machine learning algorithm that works well for classification and regression tasks. It operates by constructing multiple decision trees during training and outputting the mode or mean prediction of individual trees.
Training the Model
For this project, I used a dataset of song features and user ratings to train the random forest model. I used Python and the scikit-learn library for training the model. Here’s a snippet of the training process:
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestRegressor
# Load data
tracks_df = pd.read_csv('rated.csv')
# Preprocess data
tracks_df = pd.get_dummies(tracks_df, columns=['genres', 'artist_id'])
X = tracks_df.drop('rating', axis=1)
y = tracks_df['rating']
# Split data into training and test sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Train the model
model = RandomForestRegressor(n_estimators=100, random_state=42)
model.fit(X_train, y_train)
Evaluating the Model
I evaluated the model using cross-validation and calculated metrics such as mean absolute error (MAE), mean squared error (MSE), and R² score:
from sklearn.model_selection import cross_val_score, KFold
from sklearn.metrics import mean_absolute_error, mean_squared_error, r2_score
import numpy as np
kf = KFold(n_splits=5, shuffle=True, random_state=42)
scores = {'MAE': [], 'MSE': [], 'R2': []}
for train_index, test_index in kf.split(X):
X_train, X_test = X.iloc[train_index], X.iloc[test_index]
y_train, y_test = y.iloc[train_index], y.iloc[test_index]
model.fit(X_train, y_train)
predictions = model.predict(X_test)
scores['MAE'].append(mean_absolute_error(y_test, predictions))
scores['MSE'].append(mean_squared_error(y_test, predictions))
scores['R2'].append(r2_score(y_test, predictions))
mean_scores = {metric: np.mean(scores[metric]) for metric in scores}
std_scores = {metric: np.std(scores[metric]) for metric in scores}
for metric in mean_scores:
print(f"{metric}: Mean={mean_scores[metric]}, STD={std_scores[metric]}")
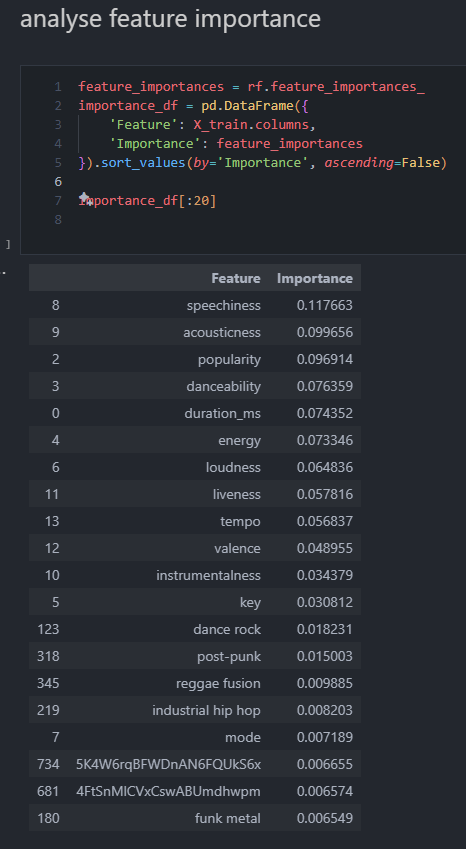
Here’s a cool look at my personal feature importance
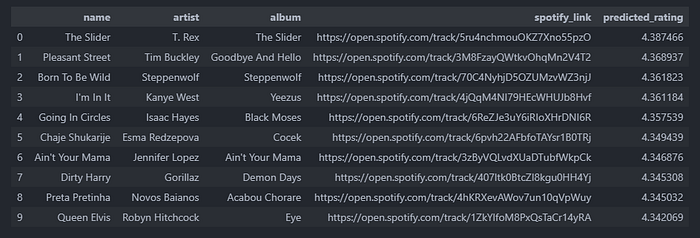
Here’s an example of some recommended songs
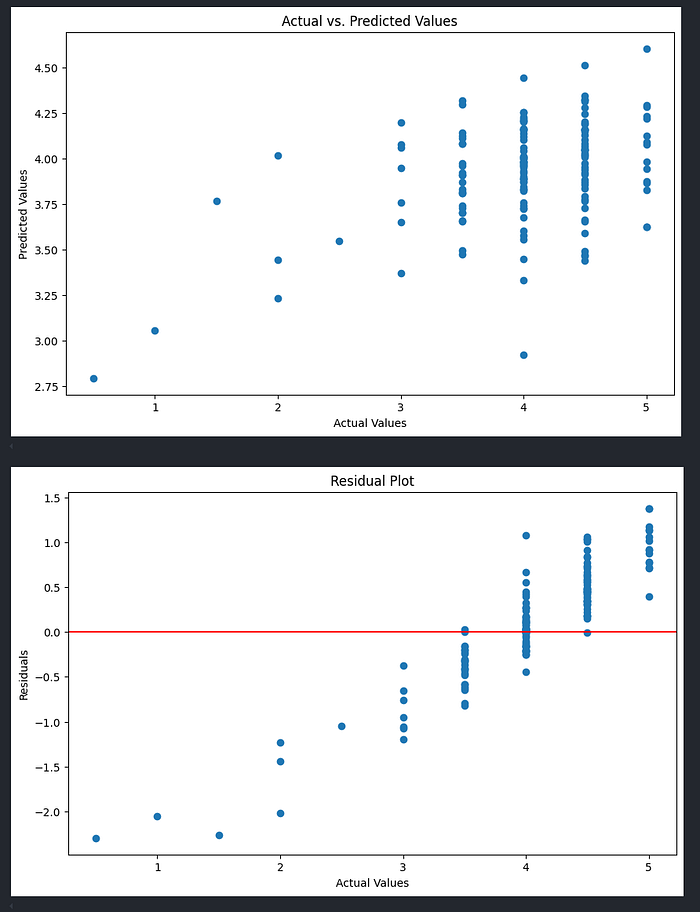
Another interesting thing to look at is the distribution of predicted ratings of the unrated songs
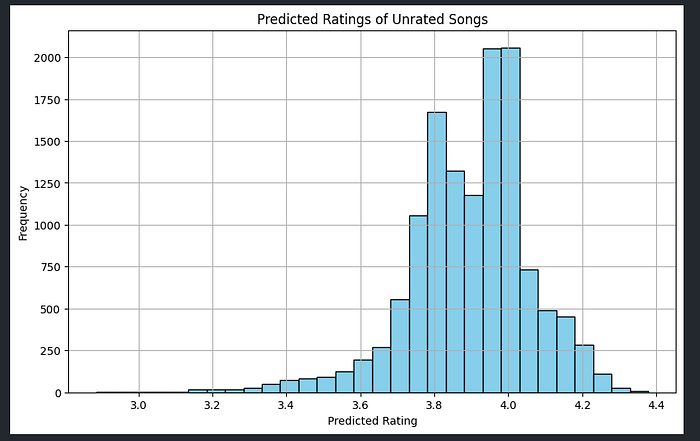
From this you can see that most of the songs are being predicted between 3.5/5 and a 4.5/5. This is interesting because it shows that a lot of the songs from the data that it has (from my ratings) are in the higher ranges of song ratings. This is the case because in general I like most songs and if I am going to listen to new songs it will have come from a friend's recommendation or me looking through discographies which means that the will most often be good songs.



